先水一下
终于有空来写博客了,这个月有点忙(有点懒),好了,进入正题
今天是要来记录一下 python动态爬取页面的,我们要爬取的页面就是
豆瓣2016年度榜单
让我们看一下源代码,按 F12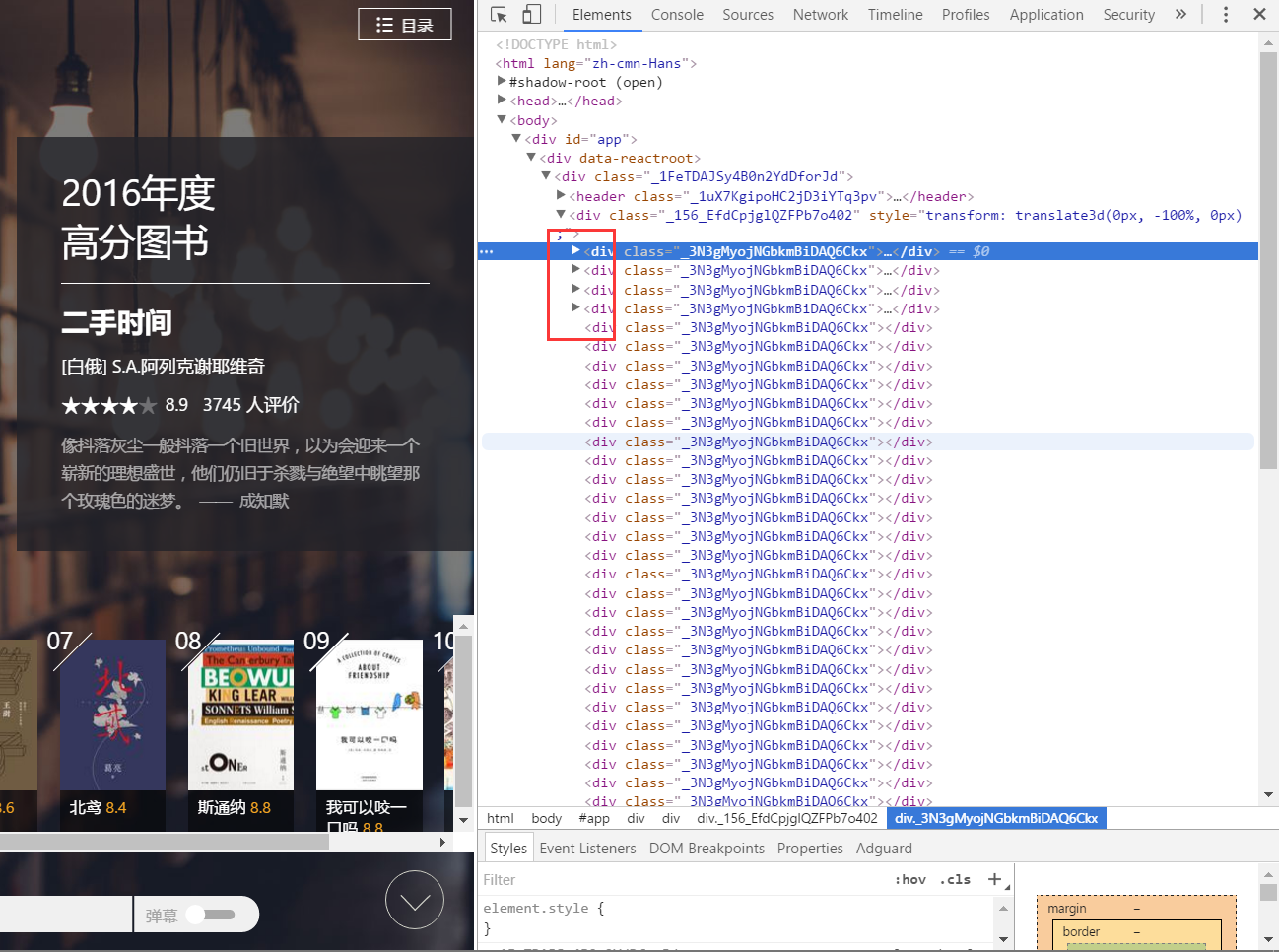
可以看到,这些页面会随着你滚轮的滚动动态加载,加载的内容也不一样,我们要做的,就是找出加载的文件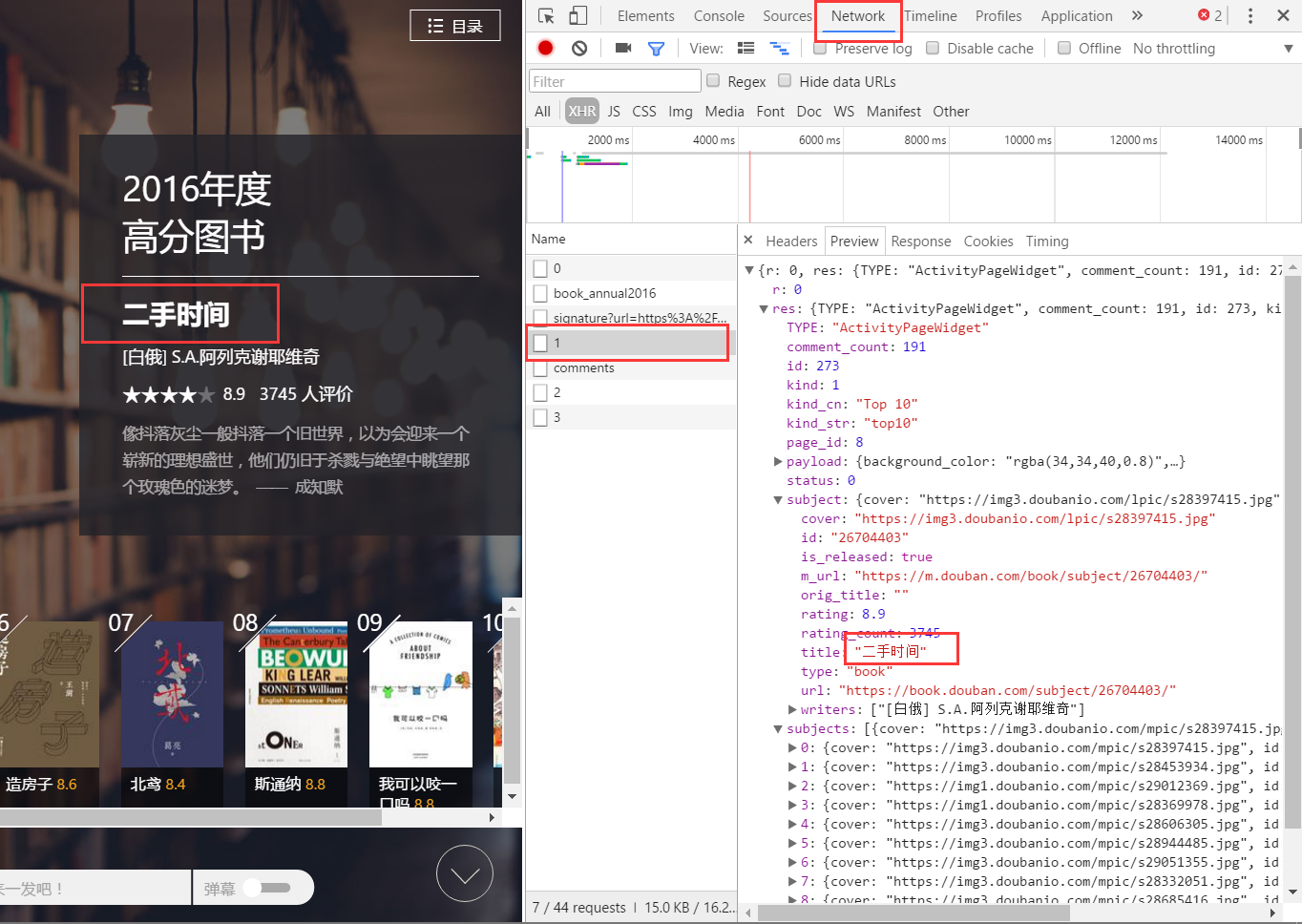
先点击 Network ,跳转到另外一个界面,随着滚轮滚动,我们可以看到,有一些东西不断被加载出来,名字是用数字编号的文件,点击看一下,发现没有,我们要找的东西就在这里!
一开始我是以为这些文件全都是保存各个书信息的json,用一个循环可以直接找出我们要的信息,点了其他几个文件才发现,其实不是的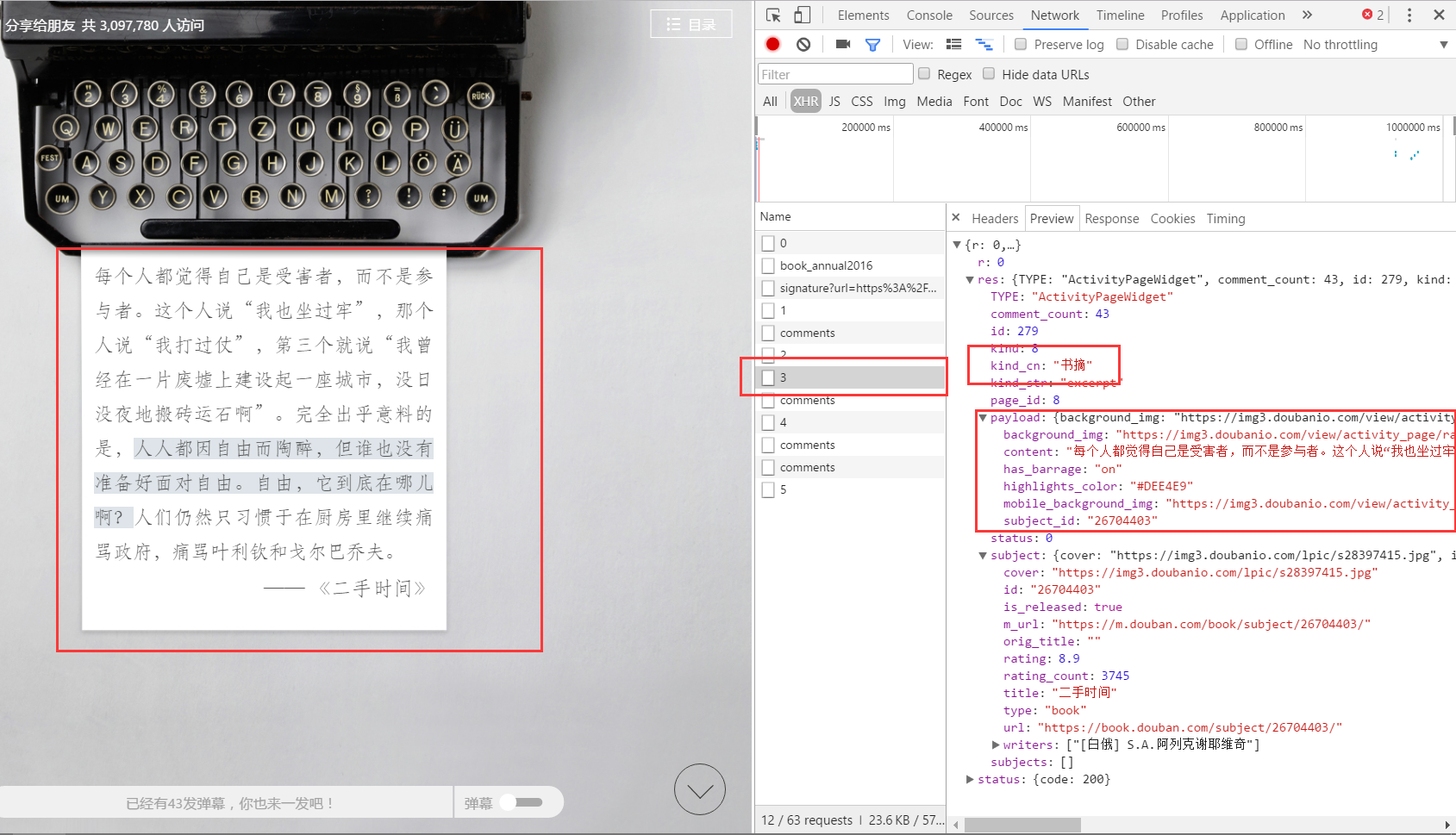
注意到 json 里面有一个 key: kind_cn,我们可以用这个来判断
由于豆瓣这个年度榜单没有页码,我们就手动滚到最底部(或者滚到你想要的位置)然后查看对应的数字文件来找到对应的页码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73import requests
import json
#引入MongoDB
from pymongo import MongoClient
#MongoDB的操作,我们会在其他博文细讲
client = MongoClient()
db = client['Books']
book_collection = db['book']
book_title = ''
book_score = ''
title = ''
book_count = ''
book_url = ''
# IP = ''.join("113.107.112.210:8101".strip())
# proxy={'http':IP}
# 协议头
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",} ##浏览器请求头(大部分网站没有这个请求头会报错、请务必加上哦)
url = 'https://book.douban.com/ithil_j/activity/book_annual2016/widget/'
page = 1
#这里的 39 就是我自己想找的最后一个页面的数字
while page<=39:
#requests包的用法,把我们之前构造好的 url 和 页码 进行拼接,才能够爬到下一个页面,关于 requests,我会在其他博文细讲
data = requests.get(url+str(page),headers=headers)
#请求页面返回后的 json 我们用 json.loads() 这个方法,把它变成python里面的字典类型,关于json,我会在其他博文细讲
value = json.loads(data.text)
#进行判断,如果是书摘的话,就跳过
if value['res']['kind_cn']==u'书摘':
page+=1
continue
#这里面还有一个分支,有一些是 top 10 ,有一些是 top 5
if value['res']['kind_str']=='top10':
for i in range(0,10):
book_title=value['res']['subjects'][i]['title']
book_score=value['res']['subjects'][i]['rating']
book_count = value['res']['subjects'][i]['rating_count']
book_url = value['res']['subjects'][i]['url']
title = value['res']['payload']['title']
post = {
'主题':title,
'书名':book_title,
'评分':book_score,
'评分人数':book_count,
'链接':book_url
}
book_collection.save(post)
# print(book_title)
# print(book_score)
# print(book_count)
# print(book_url)
# print(title)
if value['res']['kind_str']=='top5':
for i in range(0,5):
book_title=value['res']['subjects'][i]['title']
book_score=value['res']['subjects'][i]['rating']
book_count = value['res']['subjects'][i]['rating_count']
book_url = value['res']['subjects'][i]['url']
title = value['res']['payload']['title']
post = {
'主题':title,
'书名':book_title,
'评分':book_score,
'评分人数':book_count,
'链接':book_url
}
book_collection.save(post)
print('第'+ str(page) +'页爬取完毕')
# print(value)
page+=1
最终就是这样啦,上面的代码就是全部了,其实还能把一些东西抽出来作为函数,但是我还是挺忙的(懒)所以留给读者去做了,可能以后还会更新,看吧,哈哈哈
上面有一些东西是需要细讲的,比如,json啊,MongoDB啊,我会另写博文,多多关注呀

